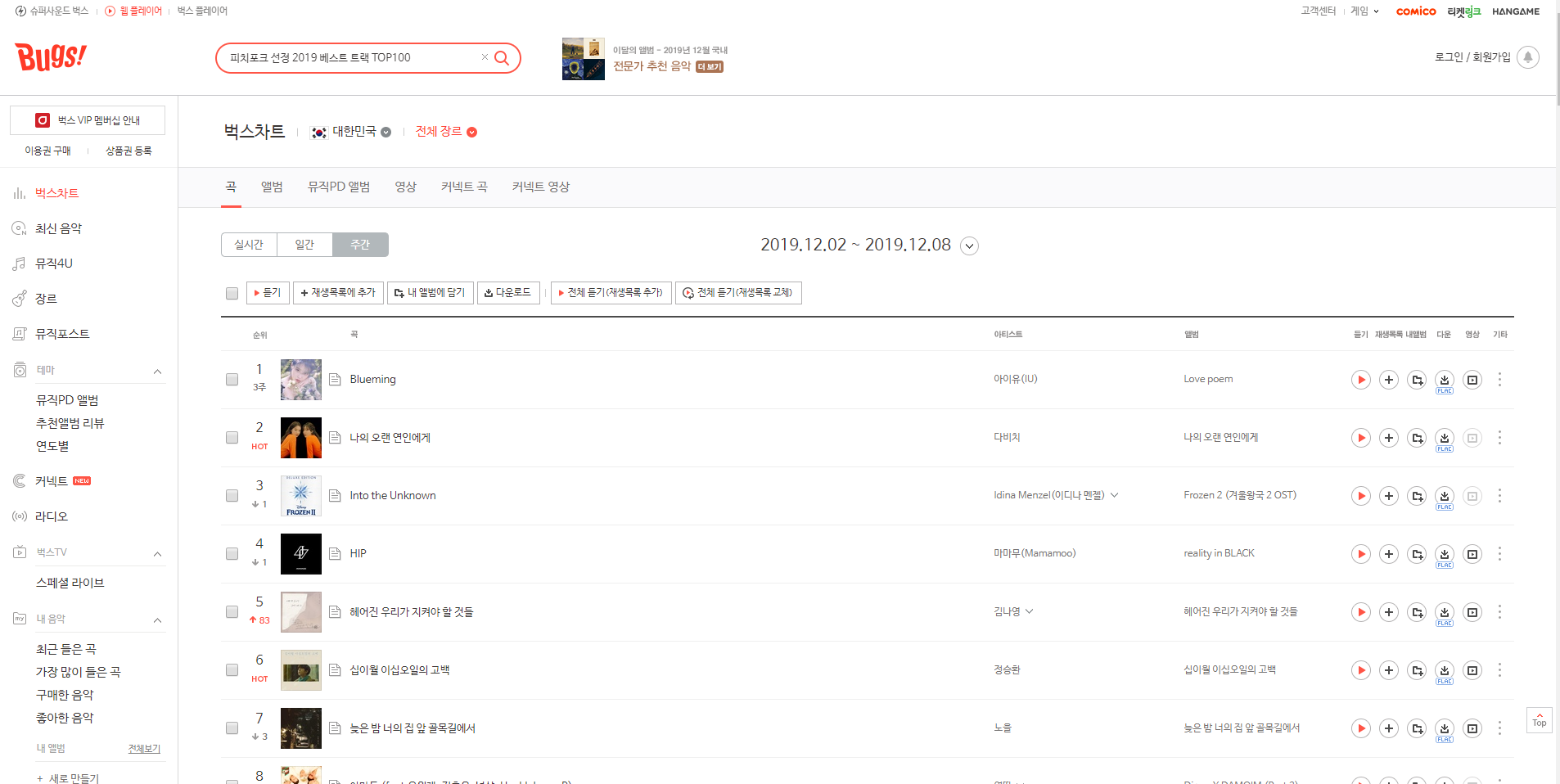
이제 뽑아온 노래 코드들로 각 페이지에 들어가서 데이터를 수집하려 한다.
모든 노래 주소는 ( https://music.bugs.co.kr/track/ + 코드 + ?wl_ref=list_tr_08_chart )
이런 형태로 되어 있어서 코드들만 바꾸면서 크롤링 하면 된다.
이제 노래 정보 페이지 형태들의 규칙성을 봐야한다.
페이지 형태는 크게 두가지로 보였으며
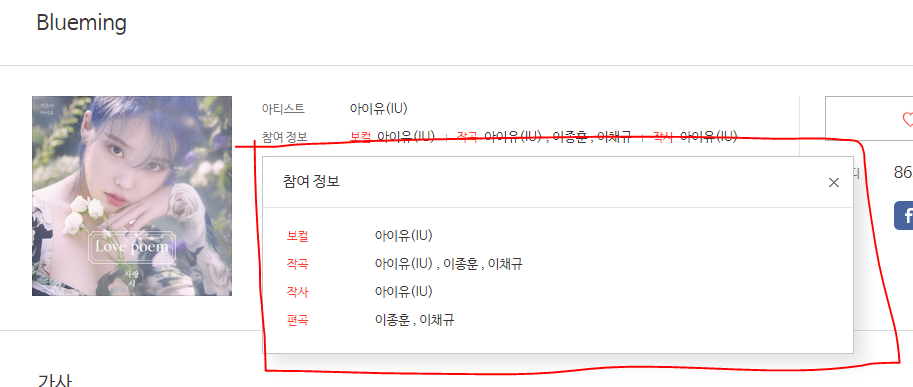
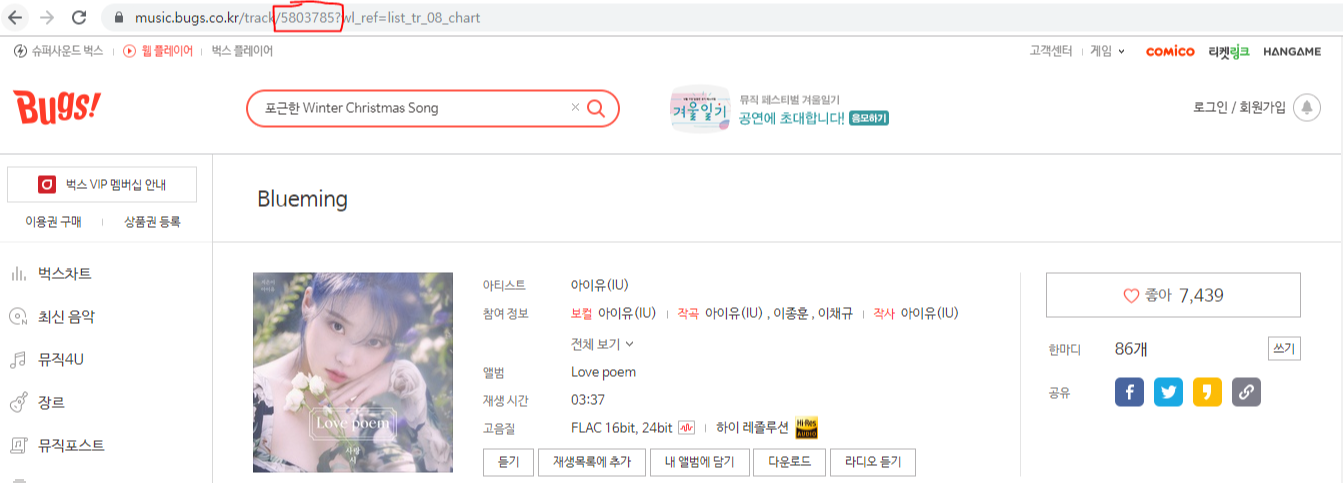
빨간 박스처럼 새창이 나오는 페이지와 안나오는 페이지로 구분했다.
새창이 나오는 페이지의 데이터만 분석 데이터로 이용했으며, 나머지 데이터는 일단 수집만 했다.

새창의 selector는 #participatingArtists으로 되어있었으며
속성을 불러왔을 때 비어있으면 노래 제목과 가수만 따로 저장을 하였다.
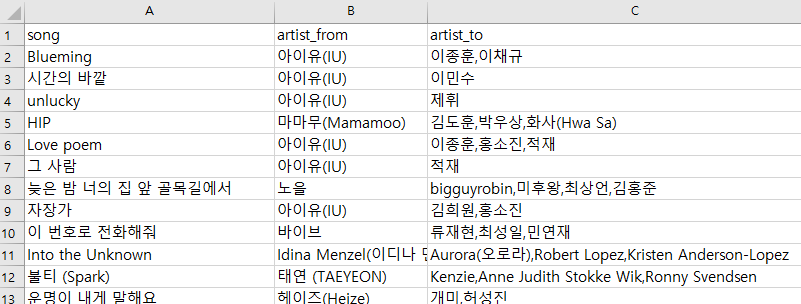
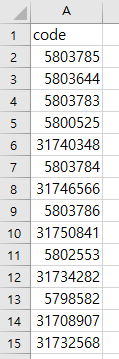
새창이 나오는 유효한 데이터는 다음과 같이 수집이 되었고
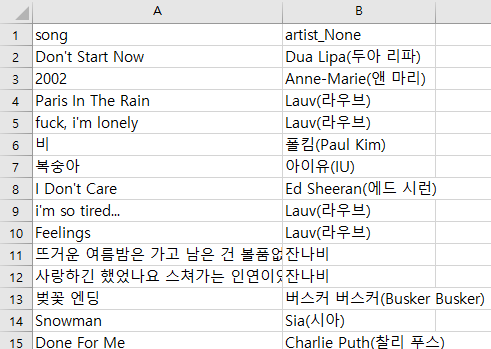
나머지 데이터는 다음과 같이 수집하여 저장 하였다.
유효한 데이터는 2,169건이고 나머지 데이터는 2,818건으로 수집되었다. (총 4,987건)
###
데이터가 필요하신 분이나 코드가 필요하신 분은
ho0shin48@gmail.com 으로 메일 보내주시면 공유해드리겠습니다.
'네트워크 분석 (연습)' 카테고리의 다른 글
| 데이터 수집(크롤링) - 1 (0) | 2019.12.13 |
|---|---|
| 네트워크 분석 연습 주제 (0) | 2019.12.13 |