먼저 원하는 분석하고자 하는 데이터가 공공데이터로 존재 하는지 찾아봤다.
역시 없었다.
그래서 스트리밍 사이트(멜론, 지니, 벅스, 바이브 등등)에서 크롤링을 할 계획을 짰다.
멜론, 지니, 바이브 등의 대다수가 반응형 웹으로 되어있어서 Selenium이 필요해 보였다.
그 중 벅스가 유일하게 Request형식으로 크롤링이 가능했고 데이터 수집 속도를 위해 벅스를 선택했다.
수집은 파이썬에서 BeautifulSoup 라이브러리를 사용하였다.
# 벅스 주간 차트 페이지
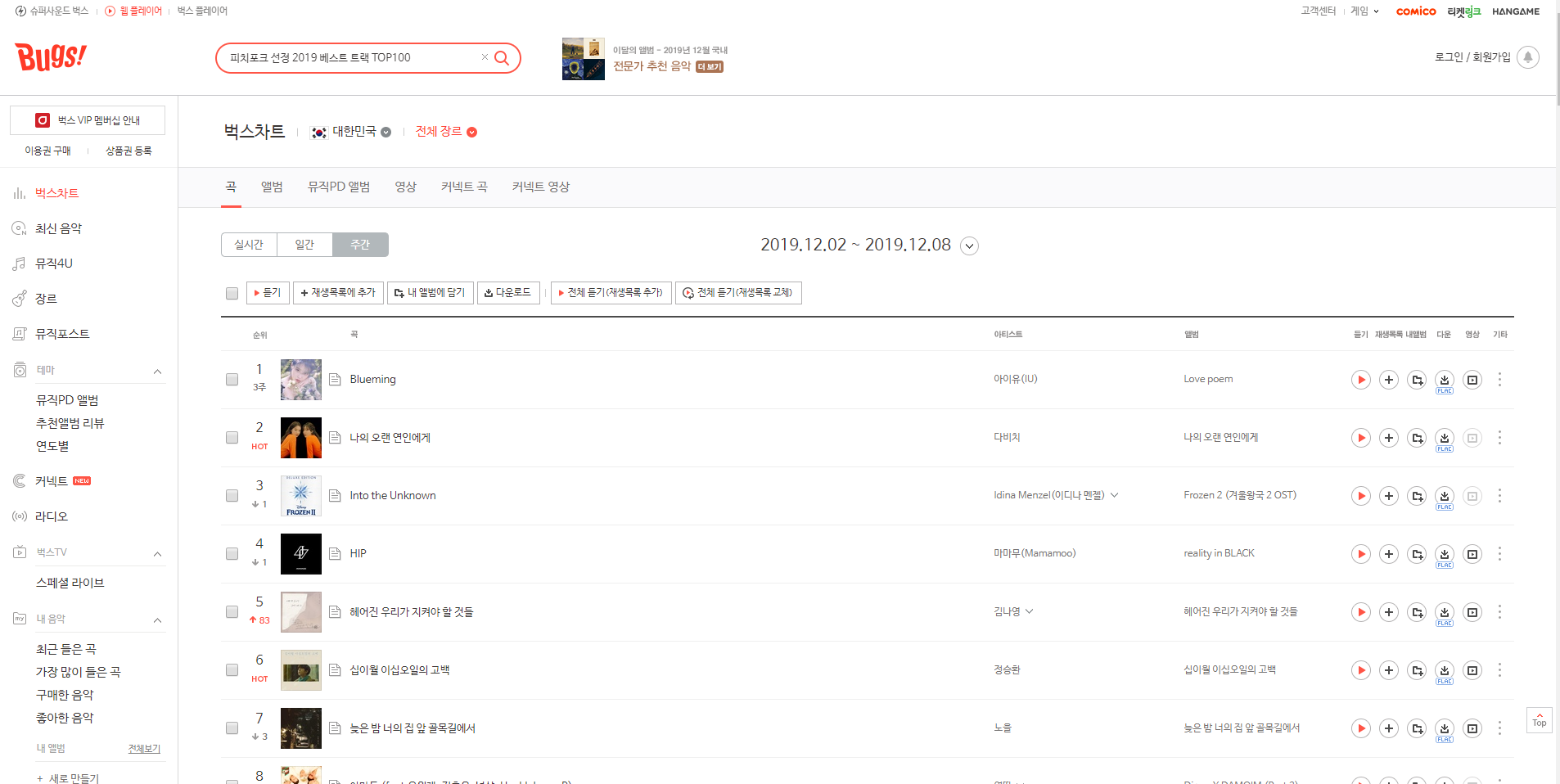
모든 노래의 데이터 수집은 불가능해서 차트에 들어간 노래만 크롤링 하기로 했다.
일일 단위는 너무 변동성 없어서 일주일 단위로 수집하기로 했다.
수집기간은 2014.01.01 ~ 2019.11.29로 했고 약 6년간의 데이터다.
먼저 각 주간 차트 페이지에 있는 모든 노래의 페이지 고유 코드를 크롤링 하기로 했다.
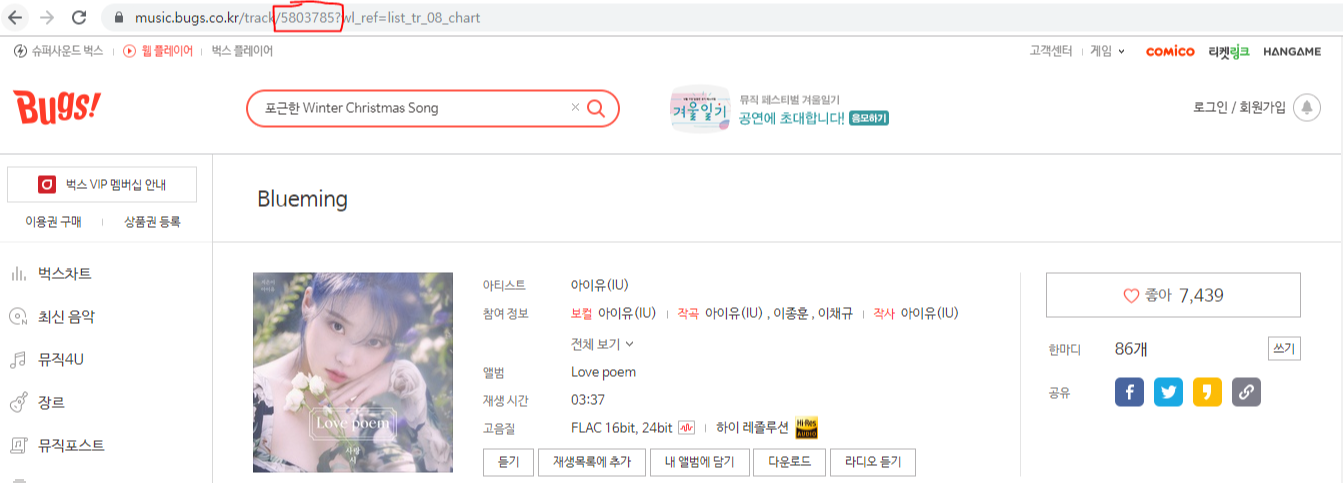
각 노래 페이지에 들어가면 빨간 박스와 같이 노래의 고유 코드가 주소로 적혀있고
주간차트 페이지의 각각의 노래 링크들 마다 고유코드를 주소로 삼고있었다.
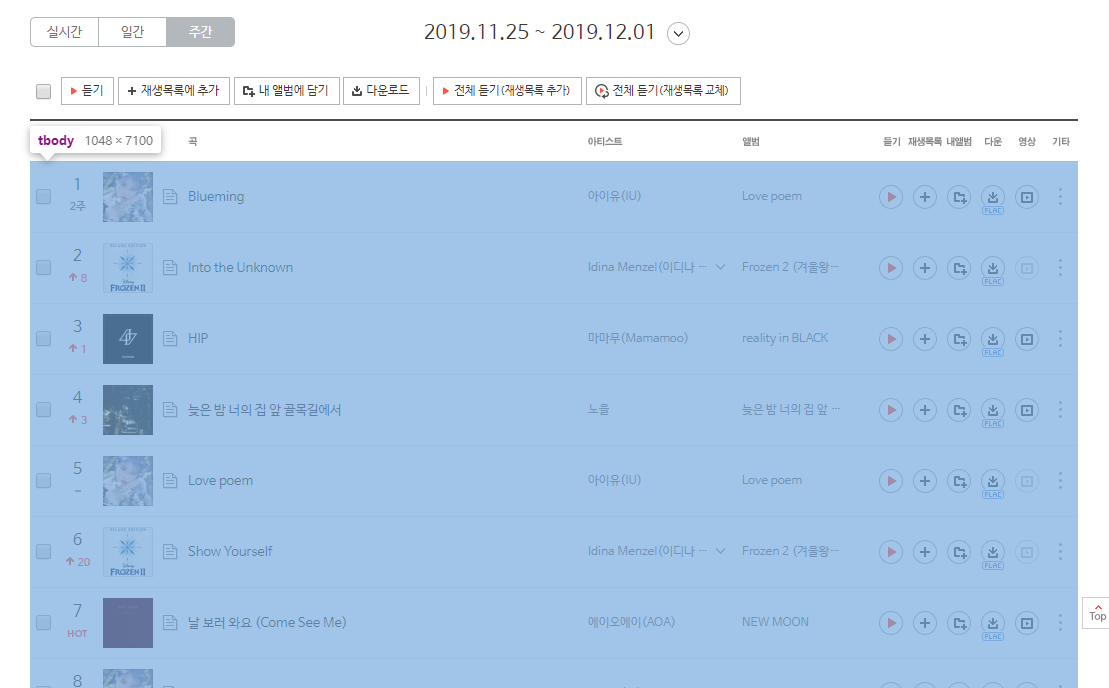
모든 노래들은 다음과 같이 tbody로 묶여있었고

tbody안에 다음과 같이 노래의 주소가 href로 적혀있었다.
그래서 모든페이지의 tbody를 불러서 그 안에 href 속성을 가지고 있고
그 주소가 "https://music.bugs.co.kr/track/ 으로 시작하는 모든 문장을 뽑아 오기로 했다.

코드는 다음과 같이 주소들을 뽑아온 뒤 코드만 뽑고
중복되는 코드는 제외 시켰다.
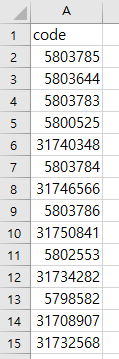
코드는 총 5478개가 수집되었다.
'네트워크 분석 (연습)' 카테고리의 다른 글
| 데이터 수집(크롤링) - 2 (2) | 2019.12.13 |
|---|---|
| 네트워크 분석 연습 주제 (0) | 2019.12.13 |